Abstract Type : Oral presentation
Abstract Submission No.: A-0720
Abstract Topic : Big Data
Evaluating LLM Agents vs. Human Responses in a Nephrology OSCE Scenario: A Human-Rated Dialogue Analysis
Yongjin Yi1, Sejoong Kim2
1Department of Internal Medicine-Nephrology, Dankook University Hospital, Korea, Republic of
2Department of Internal Medicine-Nephrology, Seoul National University College of Medicine, Korea, Republic of
Objectives : Clinical performance examination (CPX) remains the gold standard for assessing clinical reasoning. However, CPX education requires substantial resources, including trained standardized patients, dedicated facilities, and high costs. Recent advances in large language models (LLMs) enable the generation of clinically accurate virtual patients as scalable alternatives to CPX. To evaluate the quality of virtual patient (VP) responses generated by LLMs in CPX scenarios, compared to human-generated responses authored by CPX educators.
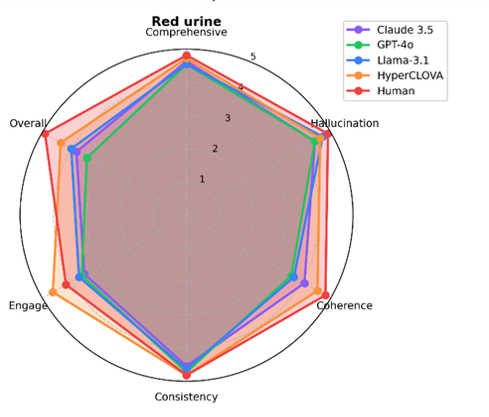
Methods : Four state-of-the-art LLMs (OpenAI GPT-4o, Anthropic Claude-3.5 Sonnet, NAVER HyperCLOVA X, and Meta LLaMA-3.1 70B) were used to simulate patient responses across three CPX scenarios (red urine, fever in pregnancy, and chronic cough). Each CPX dialogue contained 23 to 25 question-response sets. An experienced CPX educator provided the reference responses. Eleven senior medical students rated each response on six quality dimensions – comprehensiveness, coherence, accuracy, hallucination avoidance, engagement, and overall satisfaction using a 5-point Likert scale.
Results : Human expert responses achieved the highest mean overall satisfaction score (4.61, IQR [4.40-4.81]), followed by HyperCLOVA X (4.00, IQR [3.73-4.27]) and Claude-3.5 (4.00, IQR [3.67-4.33]). Claude-3.5demonstrated superior hallucination avoidance (4.45, IQR [4.21-4.70]), while HyperCLOVA X excelled in engagement metrics (4.30/5.0). LLaMA-3.1-70B consistently underperformed (2.64, IQR [2.23-3.04]).
Conclusions : LLM-powered virtual patients can produce realistic and clinically relevant responses, demonstrating potential as scalable training tools in medical education. The human-authored responses still outperform LLMs in overall quality. The Korean-optimized LLM showed particular strength in culturally nuanced medical communication, underscoring the importance of domain-specific pretraining for clinical applications.
Methods : Four state-of-the-art LLMs (OpenAI GPT-4o, Anthropic Claude-3.5 Sonnet, NAVER HyperCLOVA X, and Meta LLaMA-3.1 70B) were used to simulate patient responses across three CPX scenarios (red urine, fever in pregnancy, and chronic cough). Each CPX dialogue contained 23 to 25 question-response sets. An experienced CPX educator provided the reference responses. Eleven senior medical students rated each response on six quality dimensions – comprehensiveness, coherence, accuracy, hallucination avoidance, engagement, and overall satisfaction using a 5-point Likert scale.
Results : Human expert responses achieved the highest mean overall satisfaction score (4.61, IQR [4.40-4.81]), followed by HyperCLOVA X (4.00, IQR [3.73-4.27]) and Claude-3.5 (4.00, IQR [3.67-4.33]). Claude-3.5demonstrated superior hallucination avoidance (4.45, IQR [4.21-4.70]), while HyperCLOVA X excelled in engagement metrics (4.30/5.0). LLaMA-3.1-70B consistently underperformed (2.64, IQR [2.23-3.04]).
Conclusions : LLM-powered virtual patients can produce realistic and clinically relevant responses, demonstrating potential as scalable training tools in medical education. The human-authored responses still outperform LLMs in overall quality. The Korean-optimized LLM showed particular strength in culturally nuanced medical communication, underscoring the importance of domain-specific pretraining for clinical applications.
table1.PNG
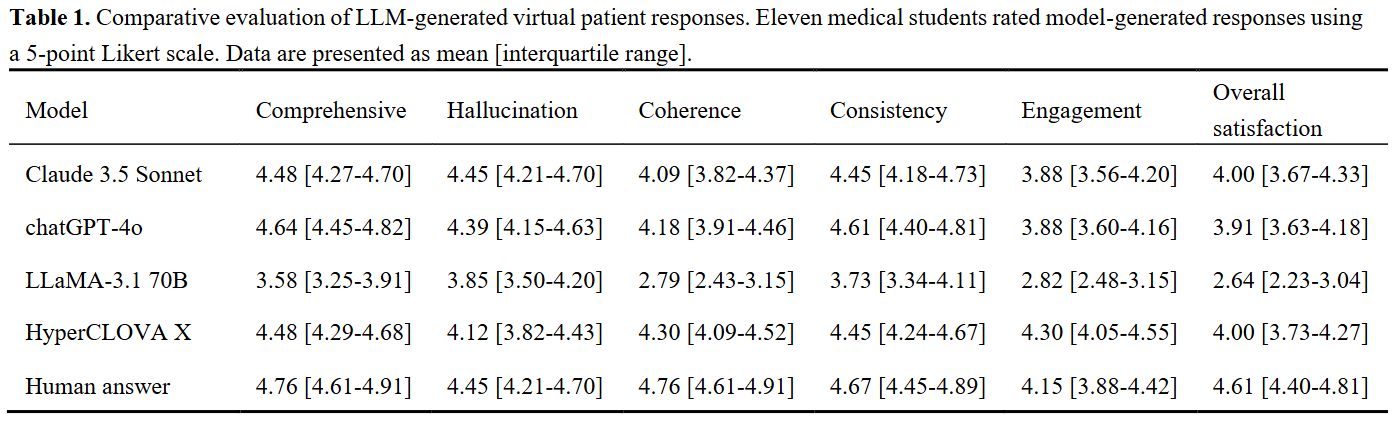
table1.PNG